

Im zweiten Artikel zur Serie informiert euch Jan heute weiter über die Möglichkeit, Data Mining bei der Personalsuche anzuwenden.
Im ersten Teil des Artikels habe ich Data Mining allgemein anhand des Beispiels „Schufa“ vorgestellt. Es geht um Techniken, die aus unüberschaubaren Informationsmengen neue, nicht triviale Erkenntnisse ableiten. In diesem Teil möchte ich auf die verschiedenen Verwendungsmöglichkeiten von Data Mining eingehen.
Funktionen von Data Mining
Die wohl wichtigsten Funktionen, die Data Mining erfüllen kann, sind:
- Segmentierung: Beispielsweise Kundengruppen identifizieren, um diese durch Marketingmaßnahmen gezielter ansprechen zu können.
- Klassifikation und Prognose: Also zum Beispiel die Einteilung in gute und schlechte Kreditnehmer oder im weiteren Sinne automatisierte Handschriftenerkennung und Spracherkennung.
- Abhängigkeitsentdeckung: Kunden die sich für Schuhcreme interessieren mögen auch „Sneaker-Socken“; „Sportfreunde Stiller“.
Im Personalbereich sind mögliche Anwendungsfelder die Analyse der Personalstruktur, Fluktuationsanalyse (Einflussfaktoren auf die Abwanderung von Mitarbeitern), Vergütungsgestaltung, Karrieremodelle und die Bewerbervorauswahl. Auf letztere bezieht sich dieser Artikel hauptsächlich.
Verfahren
Die Verfahren, die man hierfür einsetzt, hängen davon ab, was man herausfinden möchte. Eine sehr simple (aber dennoch wirkungsvolle) Methode zur Klassifikation ist z.B. der kNN-Algorithmus („k Nächste Nachbarn“). Stellen wir uns einen zweidimensionalen Raum vor, auf der X-Achse steht die Note des Hochschulabschlusses einer Person, auf der Y-Achse das vorherige Einkommen. In diesem Diagramm sind nun viele Personen eingetragen, die vom Personaler in die Kategorien „Outperformer“ und „Underperformer“ eingeteilt werden sollen. Die Kategorie, in die ein Bewerber gehört, wird nach der Einstellung sichtbar, das heißt, man kann von den Daten der früheren Fälle über Einkommen und Alter auf die aktuellen Bewerber schließen.
Der neue Bewerber wird nun in das Diagramm eingetragen und der kNN-Algorithmus ordnet ihn derjenigen Kategorie zu, in die diejenigen früheren Bewerber fallen, die ihm am ähnlichsten sind – also die ein ähnliches Alter und ein ähnliches vorheriges Einkommen haben. Je nachdem, wie man den Wert „k“ festlegt wird entweder nur der nächstgelegene Nachbar oder die nächstgelegenen zwei, drei usw. zur Prognose herangezogen.
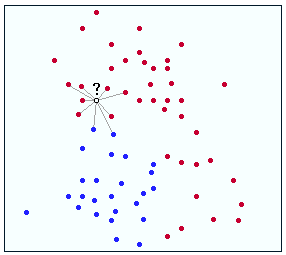 Das klingt trivial? Nichts, wofür man unbedingt einen Computer oder ausgefeilte Techniken bräuchte? Okay, aber wie sieht es aus, wenn man anstatt zwei Dimensionen (Einkommen, Alter) plötzlich 10 Dimensionen hat – Abiturnoten, Studiumsabschluss, Studiendauer, Anzahl Jobwechsel usw. – dann ist es nicht mehr möglich, die Daten per Hand zuzuordnen. Hier können nur spezialisierte Programme weiterhelfen. Die gibt es übrigens häufig sogar kostenlos. Zu empfehlen ist – je nach Anwendungsfeld Weka und Rapidminer.
Das klingt trivial? Nichts, wofür man unbedingt einen Computer oder ausgefeilte Techniken bräuchte? Okay, aber wie sieht es aus, wenn man anstatt zwei Dimensionen (Einkommen, Alter) plötzlich 10 Dimensionen hat – Abiturnoten, Studiumsabschluss, Studiendauer, Anzahl Jobwechsel usw. – dann ist es nicht mehr möglich, die Daten per Hand zuzuordnen. Hier können nur spezialisierte Programme weiterhelfen. Die gibt es übrigens häufig sogar kostenlos. Zu empfehlen ist – je nach Anwendungsfeld Weka und Rapidminer.
Einne ähnliche Methode wurde mal an amerikanischen Basketballspielern angewendet. Dabei wurden die Anfänge der Karrieren von erfolgreichen Topstars mit denen von jungen Talenten verglichen, um herauszufinden, welche Talente hohe Erfolgschancen haben.
Natürlich gibt es noch viele weitere Verfahren: Entscheidungsbäume, Neuronale Netzwerke und zahlreiche statistische Methoden wie z.B. Regression. Manche Methoden kommen dabei mit fehlenden Werten besser klar, andere können nur mit Zahlenwerten als Ausgangsinformationen umgehen, manche eignen sich zur Prognose, andere zur Abhängigkeitsanalyse.
Neben den grundlegenden Verfahren wurden für die einzelnen Methoden im Laufe der Jahre immer weitere Verbesserungsmöglichkeiten entwickelt, die jedoch nur in bestimmten Situationen sinnvoll sind. Man kann das mit dem Tuning eines Autos vergleichen: Bei einem Sportwagen nützen Geländereifen nicht viel, ein Off-Road-Fahrzeug wird hingegen kaum von einem Heckspoiler profitieren. Beim Data Mining ist es anfangs leider nicht unbedingt erkennbar, ob sich der Einsatz einer bestimmten Methode lohnt oder nicht. Daher ist man neben dem Wissen über die grundsätzlichen Eigenschaften der einzelnen Verfahren auch immer auf eine gute Intuition und auf Ausprobieren angewiesen.
Auch wenn es kein Patentrezept gibt, die Zielsetzung der Analyse sollte klar definiert sein. Denn dann ist die Überprüfung der gewählten Algorithmen nicht schwierig. Sie ist elementarer Bestandteil des Data Minings und erfolgt beispielsweise, indem man von einem kleinen Teil der bereits entschiedenen Bewerbungen, die in der Datenbank enthalten sind, die Information „Eingestellt“ oder „Nicht eingestellt“ entfernt und dann überprüft, ob der Algorithmus sie richtig zuordnen würde, wenn es neue Fälle wären. Dadurch wird unmittelbar klar, wie gut die gewählte Methode funktioniert. In den letzten Jahren wurden auch Techniken entwickelt, die diese Arbeit teilweise selbst übernehmen, das heißt, verschiedene Parameter eines Algorithmus „durchprobieren“ und somit schneller herausfinden, was die optimalen Einstellungen sind.
Die Daten
Die Daten in eine analysierbare Form zu bringen ist sicher eine weitere Herausforderung. Dabei dürfte einiges an Handarbeit anfallen aber die Standardisierungsbestrebungen im Personalwesen z.B. durch den HR-XML-Standard ebnen hier den Weg. In vielen Fällen ist dennoch die Beurteilung und das Eingreifen des Personalers notwendig.
In der Regel benötigt die Vorbereitung der Daten für eine Analyse mehr als die Hälfte des gesamten Zeitaufwands. Wichtig hierbei ist, dass die Daten so skaliert sind, dass der Algorithmus sie versteht. So kann z.B. kNN nur mit Zahlen umgehen, das heißt, Werte wie „Ja“ und „Nein“ müssen vorher in 0 und 1 umgewandelt werden. Oftmals muss man sich auch überlegen, wie man mit fehlenden Werten umgeht, z.B. wenn die Berufserfahrung eines Bewerbers unbekannt ist. Löscht man den Datensatz komplett oder versucht man den fehlenden Wert zu schätzen, z.B. indem man den Mittelwert verwenden lässt?
Man sieht hier schon, dass Data Mining an sich schon eine ziemlich komplizierte Angelegenheit ist, erst recht dann, wenn es darum geht, es fernab von grauer Lehrbuchtheorie auf einen konkreten Anwendungsfall zuzuschneiden. Im dritten und letzten Teil des Artikels möchte ich auf rechtliche und ethische Bedenken eingehen und die Anwendung von Data Mining speziell in Bezug auf die Personalauswahl nochmal etwas näher beleuchten.




